

🕔: 5 min – Technical: ✔✔✔
As described in our first article, there are significant differences within Artificial Intelligence. The exicution of a weak AI can usually be realized with existing structures and requires only program changes.
However, the implementation of machine learning usually requires a large amount of data. One of the most used data sources are ERP systems, which, unlike plant control systems, already contain a large amount of historical data.
What data is relevant?
From today’s perspective, you can never have enough data. Information that plays a minor role today may be important for future projects, and to avoid starting from scratch, it is advisable to collect it now. Projects should have a roadmap that defines the goals and the data needed.
Collecting data in production
It is important to distinguish between constant and variable information. Unlike variable information, constant information (today and in the future!) only takes up unnecessary storage space. Product-related system parameters are usually easy to store. Variable information, such as cycle times, power consumption and the like, which have not been easily recorded in the past, is much more complex.
How do I access the data?
It is of course possible to record machine settings via the HMI. In addition to the necessary expansion of the sensor technology, the question arises: How do I get relevant data directly from the control into a database? The magic word is MQTT (Message Queuing Telemetry Transport). This is an open message protocol for machine-to-machine communication that can be used to transfer telemetry data. The corresponding hardware is usually already offered by the control system manufacturers. Siemens, for example, offers CloudConnect as a retrofit for existing systems. Depending on the manufacturer and type of the CPU, this function is already included in new installations.
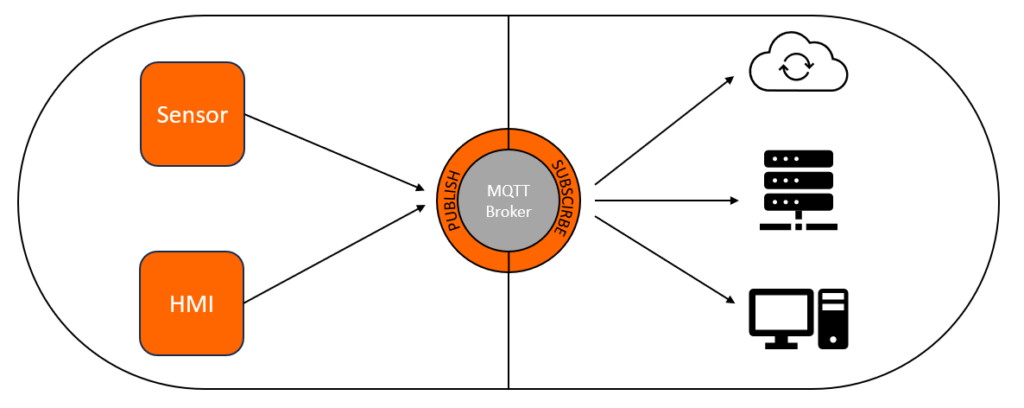
How do I save the data?
There are hardly any restrictions for further processing of the data because MQTT is an open protocol. In principle, a system should be structured in such a way that data from different sources can be merged as easily as possible in the future. In addition to local solutions, the use of a cloud service is an option. The larger the community, the greater the choice of tools. Microsoft’s Entra (formerly Azure) is not only interesting for companies that also use Business Central or Navision, but also offers numerous tools for data collection and analysis. Your own cloud systems can also be connected.
How is data merged?
It may be necessary to merge data if different system components from different vendors are involved in the overall process. This is not necessarily required for non-overlapping processes. However, when it comes to product quality, multiple sources are usually necessary (e.g., mixing, manufacturing, and curing). To be able to evaluate data in these cases, it is essential to generate unique assignments in the form of an ID. The database keys should be structured in such a way that filters and evaluations are easily possible.
Data evaluation
Since Machine Learning, in contrast to Deep Learning, has a clearly defined task, the evaluation is always intended for a specific purpose. However, there is no general rule on how to handle the data and what conclusions to draw from it. In order to proceed as efficiently as possible, it is essential to describe the project in detail beforehand. Once the data has been evaluated, it should be returned to the PLC in the form of parameters related to the model. Models usually need to be adapted or extended, especially at the beginning. Therefore, the reference to the model is important to understand which algorithm and which data were used to create the parameterization.
Hardware Requirements
Due to the “small amount of data” compared to other industries (e.g. medicine), the requirements are currently manageable and can be realized with conventional hardware. As soon as the models become more complex and significantly more data must be processed, more computing power is required. The performance of the CPU is less important, and the performance of the GPU(s) becomes more important. If this performance is not needed all the time, it is advisable to rent a server. There are already a lot of providers. Cloud services also usually provide computing power in a package.
There are an infinite number of possible applications and in the next article we will give some examples/ideas of what a project could look like. If you have any questions or want more details, do not hesitate to contact us.


