

🕔: 5 min – Technik: ✔✔✔
Wie in unserem ersten Artikel beschrieben, gibt es erhebliche Unterschiede innerhalb der Künstlichen Intelligenz. Die Umsetzung einer schwachen KI kann in der Regel mit bestehenden Strukturen realisiert werden und erfordert lediglich Programmerweiterungen.
Die Implementierung von maschinellem Lernen hingegen erfordert vor allem große Datenmengen. Eine der am häufigsten genutzten Datenquellen sind ERP-Systeme, die im Gegensatz zu Anlagensteuerungssystemen bereits eine große Menge an historischen Daten enthalten.
Welche Daten sind relevant?
Aus heutiger Sicht kann man nie genug Daten haben. Informationen, die heute eine untergeordnete Rolle spielen, können für künftige Projekte wichtig sein, und um nicht bei Null anzufangen, ist es ratsam, sie jetzt zu sammeln. Projekte sollten einen Fahrplan haben, der die Ziele und die benötigten Daten definiert.
Sammeln von Daten in der Produktion
Es ist wichtig, zwischen konstanten und variablen Informationen zu unterscheiden. Im Gegensatz zu variablen Informationen, beanspruchen konstante Informationen (heute und in der Zukunft!) nur unnötigen Speicherplatz. Die Speicherung von produktbezogenen Systemparametern ist in der Regel einfach. Wesentlich komplexer wird es bei variablen Informationen, die in der bisherigen Praxis nicht ohne weiteres erfasst werden konnten, wie z.B. Zykluszeiten, Stromverbrauch und Ähnliches.
Wie kann ich auf die Daten zugreifen?
Natürlich ist es möglich, Maschineneinstellungen über das HMI zu erfassen. Neben dem notwendigen Ausbau der Sensorik stellt sich aber auch die Frage: Wie bekomme ich relevante Daten direkt von der Steuerung in eine Datenbank? Das Zauberwort heißt MQTT (Message Queuing Telemetry Transport). Dabei handelt es sich um ein offenes Nachrichtenprotokoll für die Machine-to-Machine-Kommunikation, das zur Übertragung von Telemetriedaten genutzt werden kann. Die entsprechende Hardware wird in der Regel bereits von den Steuerungsherstellern angeboten. Siemens zum Beispiel bietet CloudConnect als Nachrüstung für bestehende Anlagen an. Je nach Hersteller und Typ der CPU ist diese Funktion bei Neuinstallationen bereits enthalten.
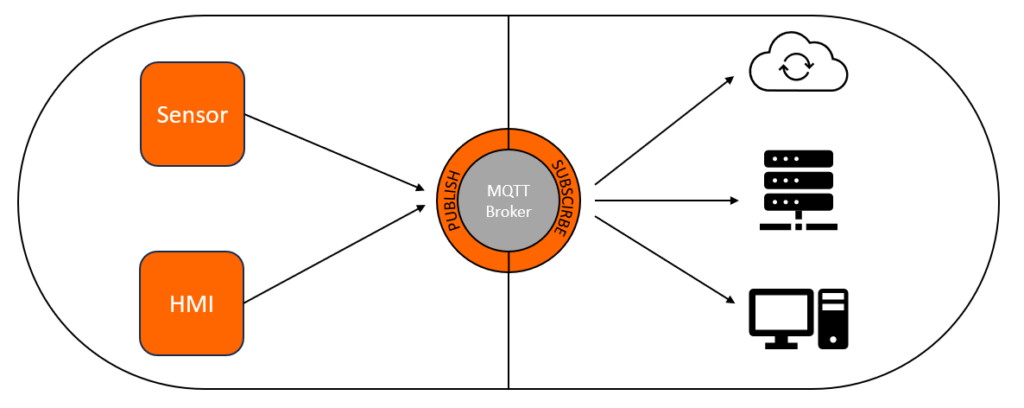
Wie speichere ich die Daten?
Für die Weiterverarbeitung der Daten gibt es kaum Einschränkungen, da MQTT ein offenes Protokoll ist. Grundsätzlich sollte ein System so aufgebaut sein, dass Daten aus verschiedenen Quellen in Zukunft möglichst einfach zusammengeführt werden können. Neben lokalen Lösungen ist auch die Nutzung eines Cloud-Dienstes eine Option. Je größer die Gemeinschaft ist, desto größer ist auch die Auswahl an Tools. Microsofts Entra (ehemals Azure) ist nicht nur für Unternehmen interessant, die auch Business Central oder Navision einsetzen, sondern bietet auch zahlreiche Tools zur Datenerfassung und -analyse. Auch eigene Cloud-Systeme können angebunden werden.
Wie werden die Daten zusammengeführt?
Eine Zusammenführung von Daten kann notwendig sein, wenn verschiedene Systemkomponenten von unterschiedlichen Herstellern am Gesamtprozess beteiligt sind. Bei sich nicht überschneidenden Prozessen ist dies nicht unbedingt erforderlich. Wenn es jedoch um die Produktqualität geht, sind in der Regel mehrere Quellen erforderlich (z. B. Mischen, Herstellen und Aushärten). Um in diesen Fällen Daten auswerten zu können, ist es unerlässlich, eindeutige Zuordnungen in Form einer ID zu generieren. Die Datenbankschlüssel sollten so strukturiert sein, dass Filter und Auswertungen leicht möglich sind.
Datenauswertung
Da Machine Learning im Gegensatz zu Deep Learning eine klar definierte Aufgabe hat, ist die Auswertung immer für einen bestimmten Zweck bestimmt. Allerdings gibt es keine allgemeine Regel, wie mit den Daten umzugehen ist und welche Schlüsse daraus zu ziehen sind. Um möglichst effizient vorgehen zu können, ist es unerlässlich, das Projekt vorher genau zu beschreiben. Nach der Auswertung der Daten sollten diese in Form von Parametern, die sich auf ein Modell beziehen, an die SPS zurückgegeben werden. Modelle müssen in der Regel angepasst oder erweitert werden, insbesondere zu Beginn. Daher ist der Hinweis auf das Modell wichtig, um zu verstehen, welcher Algorithmus und welche Daten zur Erstellung der Parametrierung verwendet wurden.
Hardware-Anforderungen
Aufgrund der “kleinen Datenmengen” im Vergleich zu anderen Branchen (z.B. Medizin) sind die Anforderungen derzeit überschaubar und können mit herkömmlicher Hardware realisiert werden. Sobald die Modelle komplexer werden und deutlich mehr Daten verarbeitet werden müssen, wird mehr Rechenleistung benötigt. Die Leistung der CPU wird weniger wichtig, die Leistung der GPU(s) wird wichtiger. Wenn diese Leistung nicht ständig benötigt wird, ist es ratsam, einen Server zu mieten. Hier gibt es bereits eine Vielzahl von Anbietern. Auch Cloud-Dienste bieten in der Regel Rechenleistung in einem Paket an.
Es gibt unendlich viele mögliche Anwendungen und im nächsten Artikel werden wir einige Beispiele/Ideen geben, wie ein Projekt aussehen könnte. Wenn Sie Fragen haben oder weitere Details wünschen, zögern Sie nicht, uns zu kontaktieren.


